
计算机视觉
计算机视觉能力
1、掌握 “将计算机视觉应用转化为具体任务” 的能力
2、学会开发和训练 “处理图像、视频等视觉数据” 的模型;
3、了解计算机视觉领域的 “现状与未来方向”—— 这也是本学年新增部分内容的原因。
1、什么是计算机视觉
其核心是 “让机器能够看见并理解图像”,而 “图像分类” 是这一领域最基础的任务。
如果仅仅只是看见,那么这就不是计算机视觉,而是照相机。
挑战
计算机理解图片靠的是像素值
当同一件物体,在摄像头经过平移后,这对于人而言,不是什么问题,但是对于计算机而言是一个很大的挑战,因为计算机理解图片靠的是数据张量
同理,光照条件、背景干扰、背景物体、物体缩放、类内差异(同一种猫有很多颜色,但是都是属于同一类)、上下文依赖。都会影响计算机去理解图片内容
图像分类的探索
(1)探索
前人对于图像分类尝试利用传统算法那样,构造出一种硬规则,就是现在图像中寻找边缘,然后再生成边缘图案,观察其中重要的图案如角点,再根据角点的特征进行分类。但是这个拓展起来十分困难,而且要对每个物体都制定一个严格的规则。为此这个图像分类算法没有取得很大的成功
(2)新发现
机器学习带来了一种数据驱动方法
第一步:收集带有标签的图像数据集
第二步:使用机器学习算法训练分类器(本质上就是构建一个训练函数,该函数接收训练数据中的图像及其对应的标签,然后构建一个能够将图像与标签关联起来的模型)
第三步:在新的图像上评估这个分类器(本质上一个名为预测的函数,该函数接收训练好的模型和一些测试图像)
最近邻分类器
有5张图像,还有1张查询图像,我们要做的就是找出训练数据中哪一张图像与这张查询图像最相似,要做到这一点,就要用到距离函数,这个距离函数需要接收两张图像,
也就是将查询图像与每一张训练图像进行配对比较,然后返回一个数值,这个数值用来定义这两张输入图像之间的相似度,最常用的计算相似度的方法是L1距离,是指两个点在坐标系上绝对差值的总和(也就是两直角边之和)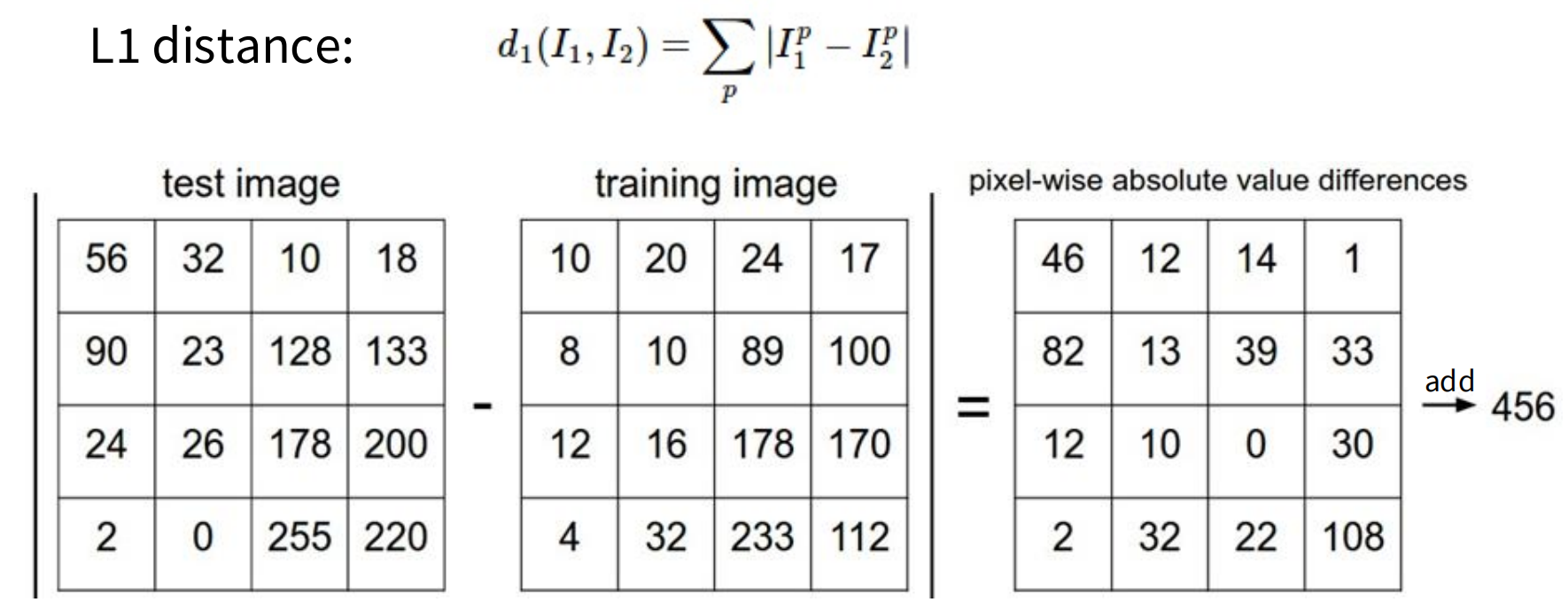
除了L1距离方法,还有L2,L2就是两点间的直线距离
但是最近邻出现了一个问题,抗干扰能力太差了,因为他在预测阶段是逐个和训练数据比对,看哪个相似度最高,但是万一不对怎么办?
故可以用k近邻,他在预测阶段是逐个和训练数据比对,找前k个相似度最高的
但是k近邻的预测阶段时间复杂度好高呀,于是就有了线性分类
线性分类的核心是通过线性变换将 “样本特征” 转化为 “类别分数”,公式非常简洁:s = W *x + b
正则化:在训练中更差,在测试中更好
四大基础
深度学习基础(Deep Learning Basics):涵盖线性分类、正则化、优化和神经网络原理 。
视觉感知与理解(Perceiving and Understanding the Visual World):任务对齐模型(如前述分割检测任务) 。
生成与交互式智能(Generative and Interactive Visual Intelligence):包括自监督学习、生成模型和语言模型 。
人本应用(Human-Centered Applications):聚焦伦理、影响和实际部署 。
早期课程重点为构建基础模型(如图像分类),逐步过渡到先进主题 。


评论