
python数据分析刷题
01 查看数据
DA1 用pandas查看牛客网用户数据
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
你可以使用pandas打开文件,偷偷看一下里面的内容,请输出你看到的前6行数据。
输入描述:
数据集直接从当前目录下的Nowcoder.csv文件中读取。
输出描述: 输出该数据集的前6行,如下所示:


DA2 牛客网用户数据集的大小
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
你不需要输出全部数据,请直接告诉我们这个数据集的大小,即行数与列数。
输入描述:
数据集直接从当前目录下的Nowcoder.csv文件中读取。
输出描述:
输出该数据集的行数与列数,如下所示:
DA3 牛客网的第11位用户
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
现在牛牛想知道这个数据集中第11行的用户的全部信息,请你帮他输出一下。
输入描述:
数据集直接从当前目录下的Nowcoder.csv文件中读取。
输出描述:
输出该数据集第11行的全部信息,每列信息单独成行,如下所示: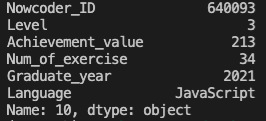
DA4 统计牛客网部分用户使用语言
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
现在牛牛想知道这个数据集中第10行到第20行的用户的常用语言分别是什么,请你帮他输出一下。
输入描述:
数据集直接从当前目录下的Nowcoder.csv文件中读取。
输出描述:
输出该数据集第10行到第20行的常用语言,每行数据单独成行,如下所示: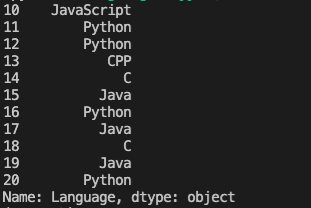
02 数据索引
DA6 查看牛客网哪些用户使用Python
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
如果你想知道哪些人经常使用Python这门语言,并且他们的其他信息是怎么样的,该怎么输出?
输入描述:
数据集直接从当前目录下的Nowcoder.csv文件中读取。
输出描述:
输出该数据集中语言为Python对应的所有列的信息,包括列号。

DA7 牛客网Python用户的成就值
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
假如你正在学习Python,你想知道牛客网的Python用户的成就值都有多高,请问该如何输出?
输入描述:
数据集直接从当前目录下的Nowcoder.csv文件中读取。
输出描述:
输出该数据集中语言为Python对应的成就值这一列的信息,包括列号。

03 逻辑运算
04 中级函数
05 数据清洗
06 json处理
07 分组聚合
08 合并
09 排序


评论