
【Pandas】数据结构DataFrame
一、DataFrame的创建
1、直接通过字典创建DataFrame
【运行结果】
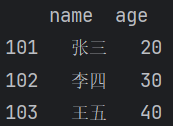
2、通过字典创建时指定列的顺序和行索引
【运行结果】
二、DataFrame的常用属性
| 属性 | 说明 |
|---|---|
| index | DataFrame的行索引 |
| columns | DataFrame的列标签 |
| values | DataFrame的值 |
| ndim | DataFrame的维度 |
| shape | DataFrame的形状 |
| size | DataFrame的元素个数 |
| dtypes | DataFrame的元素类型 |
| T | 行列转置 |
| loc[] | 显式索引,按行列标签索引或切片 |
| iloc[] | 隐式索引,按行列位置索引或切片 |
| at[] | 使用行列标签访问单个元素 |
| iat[] | 使用行列位置访问单个元素 |
loc[] 显式索引,按行列标签索引或切片
【运行结果】
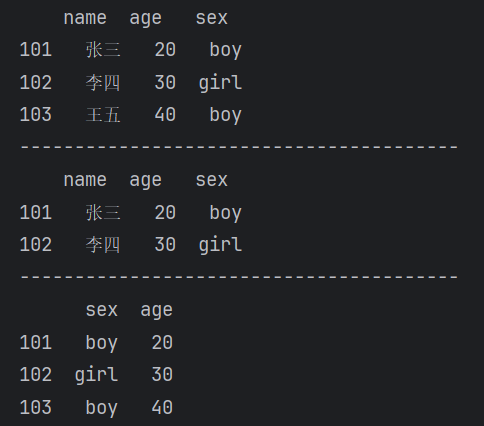
iloc[] 隐式索引,按行列位置索引或切片
【运行结果】
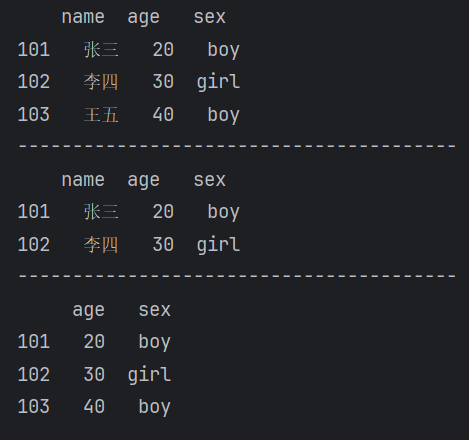
at[] 使用行列标签访问单个元素
iat[] 使用行列位置访问单个元素
三、DataFrame的常用方法
| 方法 | 说明 |
|---|---|
| head() | 查看前n行数据,默认5行 |
| tail() | 查看后n行数据,默认5行 |
| isin() | 元素是否包含在参数集合中 |
| isna() | 元素是否为缺失值 |
| sum() | 求和 |
| mean() | 平均值 |
| min() | 最小值 |
| max() | 最大值 |
| var() | 方差 |
| std() | 标准差 |
| median() | 中位数 |
| mode() | 众数 |
| quantile() | 指定位置的分位数,如quantile(0.5) |
| describe() | 常见统计信息 |
| info() | 基本信息 |
| value_counts() | 每个元素的个数(每行的个数) |
| count() | 非空元素的个数 |
| drop_duplicates() | 去重 drop_duplicates(subset=[列名1, 列名2]) |
| sample() | 随机采样 |
| replace() | 用指定值代替原有值 |
| equals() | 判断两个DataFrame是否相同 |
| cummax() | 累计最大值 |
| cummin() | 累计最小值 |
| cumsum() | 累计和 |
| cumprod() | 累计积 |
| diff() | 一阶差分,对序列中的元素进行差分运算,也就是用当前元素减去前一个元素得到差值,默认情况下,它会计算一阶差分,即相邻元素之间的差值。参数: periods:整数,默认为 1。表示要向前或向后移动的周期数,用于计算差值。正数表示向前移动,负数表示向后移动。 axis:指定计算的轴方向。0 或 'index' 表示按列计算,1 或 'columns' 表示按行计算,默认值为 0。 |
| sort_index() | 按行索引排序 |
| sort_values() | 按某列的值排序,可传入列表来按多列排序,并通过ascending参数设置升序或降序 sort_values([列名1, 列名2, …], asceding=[True, False, …]) |
| nlargest() | 返回某列最大的n条数据 nlargest(n, [列名1, 列名2, …]) |
| nsmallest() | 返回某列最小的n条数据 nsmallest(n, [列名1, 列名2, …]) |
对指定列求平均值
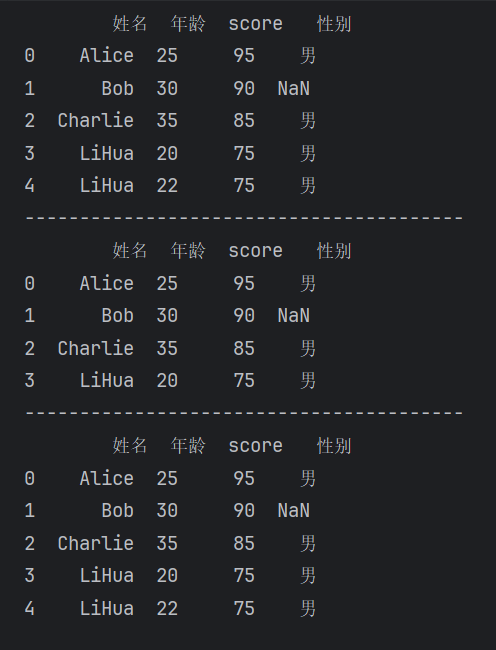
mean()去重
drop_duplicates()【运行结果】
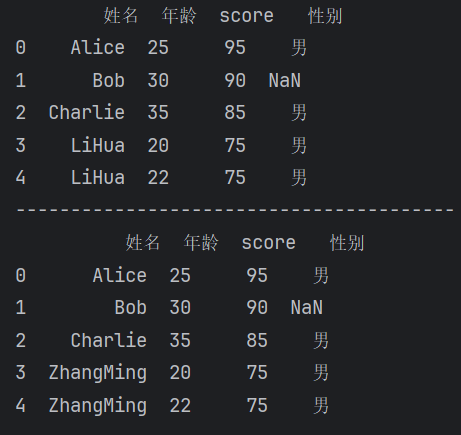
用指定值代替原有值
replace()【运行结果】
判断两个DataFrame是否相同
equals()【运行结果】
False
True累计最大值
cummax()axis=0是按列,axis=1是按行
比较的时候,第一个数不动,从第二个数开始比较,谁大就取谁
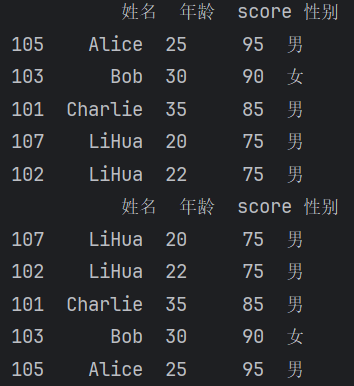
按指定字段排序
sort_values()【运行结果】
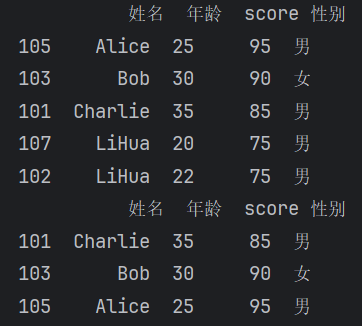
返回某列最大的几条数据
nlargest()【运行结果】
四、DataFrame的布尔索引
import pandas as pd
df = pd.DataFrame(
data={"age": [20, 30, 40, 10], "name": ["张三", "李四", "王五", "赵六"]},
columns=["name", "age"],
index=[101, 104, 103, 102],
)
print(df)
print("--"*20)
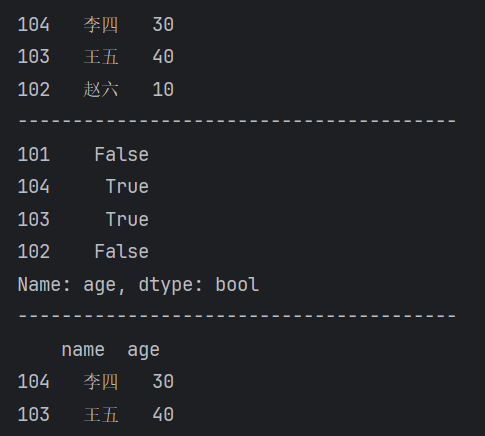
print(df["age"] > 25) # 返回布尔类型,检索哪些是年龄大于25岁的
print("--"*20)
print(df[df["age"] > 25]) # 根据布尔类型True,重新生成一个DataFrame【运行结果】
五、DataFrame的运算
1、DataFrame与标量运算
import pandas as pd
df = pd.DataFrame(
data={"age": [20, 30, 40, 10], "name": ["张三", "李四", "王五", "赵六"]},
columns=["name", "age"],
index=[101, 104, 103, 102],
)
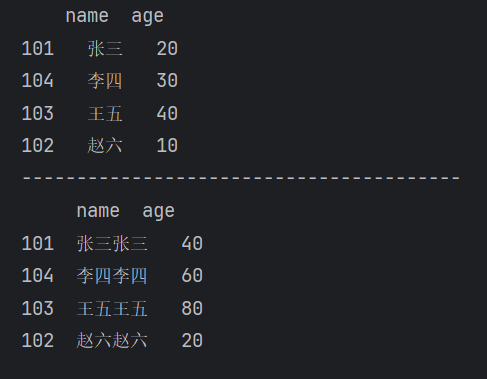
print(df)
print("--"*20)
print(df*2)【运行结果】
2、DataFrame与DataFrame运算
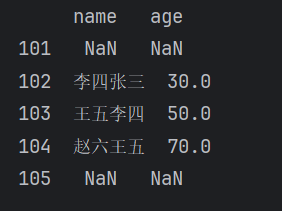
根据标签索引进行对位计算,索引没有匹配上的用NaN填充。
import pandas as pd
df1 = pd.DataFrame(
data={"age": [10, 20, 30, 40], "name": ["张三", "李四", "王五", "赵六"]},
columns=["name", "age"],
index=[101, 102, 103, 104],
)
df2 = pd.DataFrame(
data={"age": [10, 20, 30, 40], "name": ["张三", "李四", "王五", "田七"]},
columns=["name", "age"],
index=[102, 103, 104, 105],
)
print(df1 + df2)【运行结果】
六、DataFrame的更改操作
1、设置行索引
(1)通过set_index()设置行索引
【运行结果】
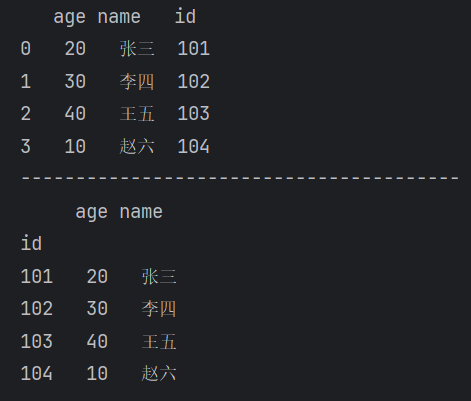
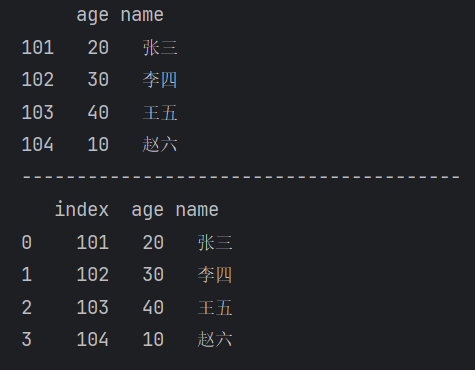
(2)通过reset_index()重置行索引
【运行结果】
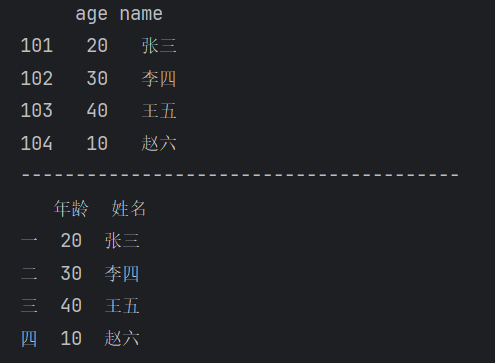
2、修改行索引名和列名
(1)通过rename()修改行索引名和列名
【运行结果】
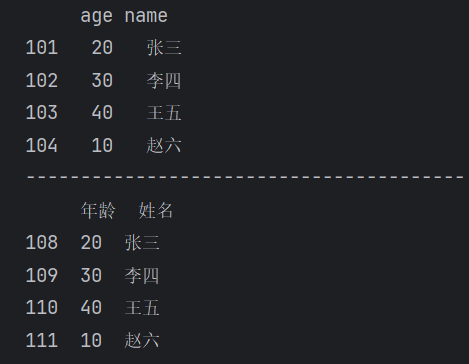
(2)将index和columns重新赋值
【运行结果】
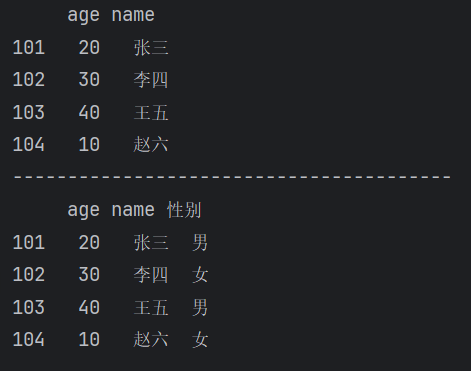
3、添加列
(1)通过 df["列名"] 添加列
【运行结果】
(2)通过 insert(loc, column, value) 插入。该方法没有inplace参数,直接在原数据上修改。
【运行结果】
4、删除列/行
(1)通过 df.drop("列名", axis=1) 删除,也可是删除行axis=0
import pandas as pd
df = pd.DataFrame(data={"age": [20, 30, 40, 10], "name": ["张三", "李四", "王五", "赵六"]},index=[101, 102, 103, 104])
print(df)
print("--"*20)
df.drop("age",axis=1,inplace=True) # 删除某列
print(df)
print("--"*20)
df.drop(103,axis=0,inplace=True) # 删除某行
print(df)【运行结果】

七、DataFrame数据的导入与导出
1、导出数据
import os
import pandas as pd
# 创建目录
os.makedirs("data", exist_ok=True)
# 创建DataFrame
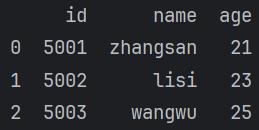
df = pd.DataFrame(data={"id":[5001,5002,5003,5004],"name":["张三","李四","王五","赵六"],"age":[21,23,25,20]})
df.set_index("id",inplace=True)
# 将df数据导出到csv文件中
df.to_csv("data/test.csv")
# 将df数据导出到json文件中
df.to_json("data/test.json",orient="records",force_ascii=False)
# 将df数据导出到剪切板中
df.to_clipboard()2、导入数据


评论