
【Pandas】数据结构Series
一、Series的创建
1、直接通过列表创建
【运行结果】
a 1
b 2
c 3
d 4
e 5
Name: hello, dtype: int64
2、通过字典创建
【运行结果】
a 1
b 2
c 3
d 4
Name: hello, dtype: int64
二、Series的常用属性
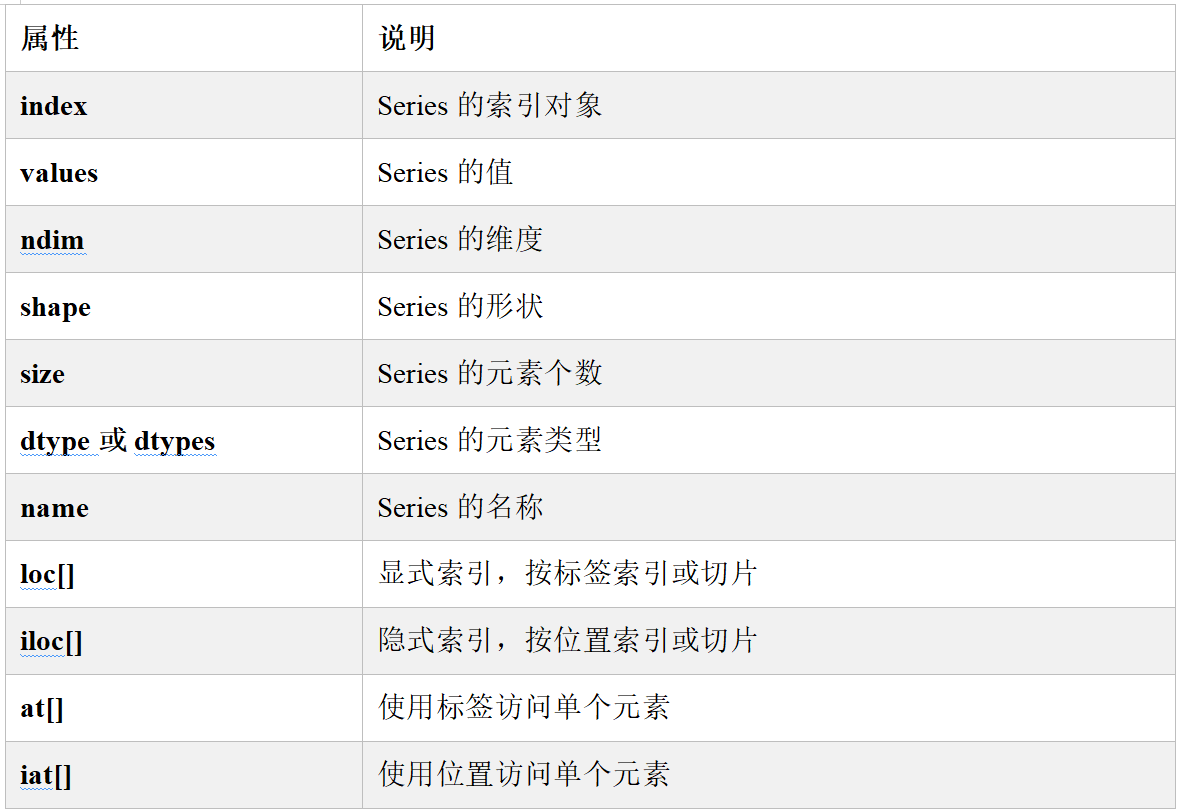
import pandas as pd
arrs = pd.Series([11,22,33,44,55],name="hello",index=["a","b","c","d","e"])
# index Series的索引对象
print(arrs.index) # Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
# values Series的值
print(arrs.values) # [11 22 33 44 55]
# ndim Series的维度
print(arrs.ndim) # 1
# shape Series的形状
print(arrs.shape) # (5,)
# size Series的元素个数
print(arrs.size) # 5
# dtype或dtypes Series的元素类型
print(arrs.dtype) # int64
print(arrs.dtypes) # int64
# name Series的名称
print(arrs.name) # hello
# loc[] 显式索引,按标签索引或切片
print(arrs.loc["c"]) # 33
print(arrs.loc["c":"d"])
# iloc[] 隐式索引,按位置索引或切片
print(arrs.iloc[0]) # 11
print(arrs.iloc[0:3])
# at[] 使用标签访问单个元素
print(arrs.at["a"]) # 11
# iat[] 使用位置访问单个元素
print(arrs.iat[3]) # 44三、Series的常用方法
| 方法 | 说明 |
|---|---|
| head() | 查看前n行数据,默认5行 |
| tail() | 查看后n行数据,默认5行 |
| isin() | 元素是否包含在参数集合中 |
| isna() | 元素是否为缺失值(通常为 NaN 或 None) |
| sum() | 求和,会忽略 Series 中的缺失值 |
| mean() | 平均值 |
| min() | 最小值 |
| max() | 最大值 |
| var() | 方差 |
| std() | 标准差 |
| median() | 中位数 |
| mode() | 众数(出现频率最高的值),如果有多个值出现的频率相同且都是最高频率,这些值都会被包含在返回的 Series 中 |
| quantile(q,interpolation) | 指定位置的分位数 q的取值范围是 0 到 1 之间的浮点数或浮点数列表,如quantile(0.5)表示计算中位数(即第 50 百分位数); interpolation:指定在计算分位数时,如果分位数位置不在数据点上,采用的插值方法。默认值是线性插值 'linear',还有其他可选值 |
| describe() | 常见统计信息 |
| value_count() | 每个元素的个数 |
| count() | 非缺失值元素的个数,如果要包含缺失值,用len() |
| drop_duplicates() | 去重 |
| unique() | 去重后的数组 |
| nunique() | 去重后元素个数 |
| sample() | 随机采样 |
| sort_index() | 按索引排序 |
| sort_values() | 按值排序 |
| replace() | 用指定值代替原有值 |
| to_frame() | 将Series转换为DataFrame |
| equals() | 判断两个Series是否相同 |
| keys() | 返回Series的索引对象 |
| corr() | 计算与另一个Series的相关系数 默认使用皮尔逊相关系数(Pearson correlation coefficient)来计算相关性。要求参与比较的数组元素类型都是数值型。 当相关系数为 1 时,表示两个变量完全正相关,即一个变量增加,另一个变量也随之增加。 当相关系数为 -1 时,表示两个变量完全负相关,即一个变量增加,另一个变量随之减少。 当相关系数为 0 时,表示两个变量之间不存在线性相关性。 例如,分析某地区的气温和冰淇淋销量之间的关系 |
| cov() | 计算与另一个Series的协方差 |
| hist() | 绘制直方图,用于展示数据的分布情况。它将数据划分为若干个区间(也称为 “bins”),并统计每个区间内数据的频数。 需要安装matplotlib包 |
| items() | 获取索引名以及值 |
四、Series的布尔索引


评论